
The allocation of attention to objects raises several intriguing questions: What are objects, how does attention access them, what anatomical regions are involved? Here, we review recent progress in the field to determine the mechanisms underlying object-based attention. First, findings from unconscious priming and cueing suggest that the preattentive targets of object-based attention can be fully developed object representations that have reached the level of identity. Next, the control of object-based attention appears to come from ventral visual areas specialized in object analysis that project downward to early visual areas. How feedback from object areas can accurately target the object’s specific locations and features is unknown but recent work in autoencoding has made this plausible. Finally, we suggest that the three classic modes of attention may not be as independent as is commonly considered, and instead could all rely on object-based attention. Specifically, studies show that attention can be allocated to the separated members of a group—without affecting the space between them—matching the defining property of feature-based attention. At the same time, object-based attention directed to a single small item has the properties of space-based attention. We outline the architecture of object-based attention, the novel predictions it brings, and discuss how it works in parallel with other attention pathways.
Avoid common mistakes on your manuscript.
To make sense of the world, we must pick and choose what sensory information will inform our thoughts and actions. Attention lies at the heart of this selection step, allowing a flexible, transient improvement of the rate and fidelity of processing of the selected target. The nature of the selection process has been the subject of decades of debate, with many studies suggesting that attention can independently select locations, features, or objects (Kravitz & Behrmann, 2011; Posner, 1980; Posner et al., 1982). Space-based attention is directed to a specific location and enhances the processing of all features at a specific location of the visual field. Feature-based attention enhances the processing of a specific feature across the entire visual field (Baylis & Driver, 1992; Driver & Baylis, 1989). Finally, object-based attention enhances only the features at the locations that define the selected object. Interestingly, it can be allocated rapidly throughout an object even if attention was initially directed to only part of the object (Egly et al., 1994). In all three cases, space-, feature-, and object-based attention, the selection can be triggered bottom-up—by a flashed cue or a sudden appearance—or top-down, by a central cue or by instructions. And in each case, the consequence is a short-lasting improvement in performance on further, typically conscious, processing of the attended location, object, or feature.
There have been several reviews of object-based attention that focused on methods and effect size (Chen, 2012; Francis & Thunell, 2022; Reppa et al., 2012). Here, we review the literature on object-based attention to determine the processes that underlie it. First, what are the targets of object-based attention? Evidence from anesthetized humans and nonhuman primates, and from unconscious priming and threat responses shows that visual input gets preattentively parsed very deeply, often to the level of complete object representations. Object-based attention appears to operate on these fully developed, preattentive object representations that have reached the level of identity and semantic connectivity. This is in stark contrast to the claims from the visual search literature that objects cannot exist until attention arrives to bind their features together (Treisman & Gormican, 1988; Wolfe & Bennett, 1997). An analysis of task demands and stimulus configurations shows how objects can indeed exist preattentively and yet fail to act that way in visual search tasks. Second, we examine several possibilities for the allocation of attention to objects. Several studies reveal that the process must involve projections from object areas to the locations and features of the object. Finally, we find that the three classic modes of attention may not be as independent as is commonly considered—instead, all three modes of selection could rely on the mechanisms of object-based attention. Studies on object-based attention directed to groups demonstrate that object-based attention in this case shows the critical nonspatial property of feature-based attention: extending over group elements but not the space between them. The processes of object-based attention may be the source of feature-based attention as well. Even so, the object-based system cannot be the only mechanism for allocating attention. There is overwhelming evidence for a space-based system controlled by saccade centers (Awh et al., 2006).
We start by briefly reviewing the three types of attentional selection before focusing on the properties required for one of them, object-based attention. This will lead us to a number of novel conclusions.
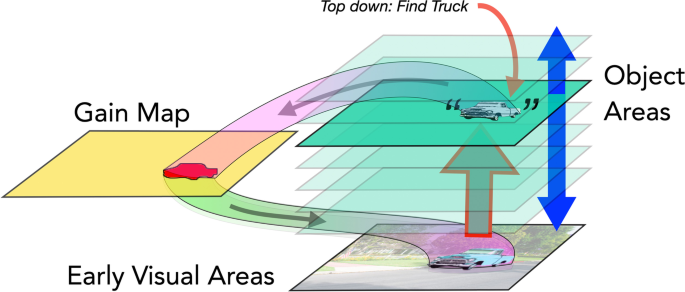
When visual items are selected from a predefined or cued location, many suggest that the effect is like shining a spotlight on that region. This is often represented as locations of high activity on a salience or priority map (Itti & Koch, 2001), or as we present in a more general framework in Fig. 1, a gain map that influences responses on corresponding location of cortical or subcortical maps. Across the attention literature, these maps have been called attention, salience, and priority maps but for the rest of this review, we will use the term “gain maps” as a general label for all of these. The hot spots on the gain map can be initiated by top-down (endogenous) or bottom-up signals (exogenous). Posner’s (1980) original cueing experiments demonstrated both. In this proposal, the effects of exogenous and endogenous cues on a gain map are identical—both lead to increased activity at the cued location which then boosts responsiveness in early visual cortex (Brefczynski & DeYoe, 1999). The difference is whether the activation of the gain map comes directly, bottom-up, from the image (e.g., a salient flash) or top-down from another cortical area that has computed the location of interest (e.g., based on expectation or a symbolic cue like an arrow). In both cases, the effects of the downward projections to early visual cortex are extended in time and space so that targets appearing briefly after the cue are processed more rapidly (Posner, 1980).
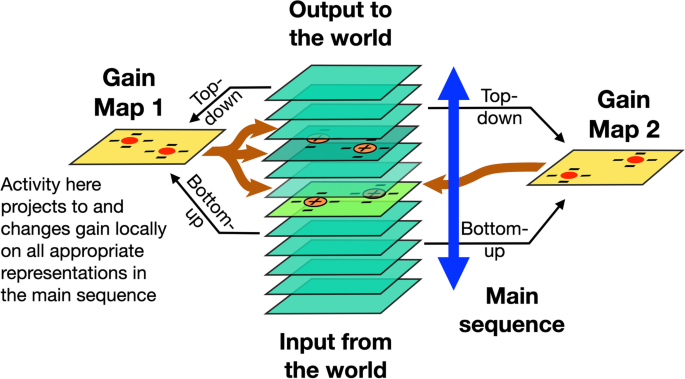
Gain is a ubiquitous factor in all connections in the brain, whether feedforward or feedback;. why would some maps, and the gain they mediate, be special? One reason is related to a second property of attention: it not only changes gain but it is limited to one or at most, a few, targets at a time (Pylyshyn & Storm, 1988). This limited capacity is most easily understood as a winner-take-all or biased competition where the target with the highest activity suppresses the others (Desimone, 1998; Lee et al., 1999; Vecera & Behrmann, 2001). This suggests that the reach of this suppression must be very wide to deal with competitors from virtually anywhere in the visual field. Consider, in contrast, activity on, say, V2 or V3. Clearly the feedforward and feedback projections from these areas change the gain elsewhere but the size of the suppressive surrounds is quite limited (Gegenfurtner et al., 1997; Shushruth et al., 2009). Local suppression may resolve local competition but cannot mediate the image-wide competition that is a critical element of attention (Franconeri et al., 2013).
A number of areas are involved in directing spatial attention (Bisley, 2011; Maunsell, 2015). Parietal areas (Corbetta & Shulman, 2002; Gazzaniga & Ladavas, 1987; Posner et al., 1984) show strong attention-linked responses and parietal lesions have devastating effects on attention (Battelli et al., 2001; Friedrich et al., 1998). Saalmann et al. (2012) have reported that the pulvinar may be part of the control of attention and Zhang et al. (2012) have argued that V1 can act as a salience (gain) map. There is also compelling evidence that saccade centers located in the frontal eye fields in the frontal cortex and the superior colliculus in the midbrain also direct spatial attention (Awh et al., 2006; Moore & Zirnsak, 2017). These findings suggest that the space-based allocation of attention can be realized in the activity patterns of these saccade/gain maps and the effects of their projections to visual cortex. Whatever the source of these projections to early visual cortex, their effect once they arrive has been described variously as an increase of gain for the stimulus at that location, a sharpening of tuning, and a suppression of responses to adjacent stimuli (Maunsell, 2015). The end result is a benefit for the stimulus at the attended location.
It is also possible to direct attention to a particular feature throughout the visual field, independently of space-based attention. Flashing a red cue, for example, leads to speeded processing of a red target at an unknown location in visual search (Lin et al., 2011). Unlike space-based attention, this processing benefit is also seen on task-irrelevant stimuli elsewhere in the visual field that share the attended feature (Saenz et al., 2002; Treue & Trujillo, 1999; White et al., 2013). Indeed, there is strong evidence that space-based and feature-based attention are operationally distinct. For example, space-based effects are seen when the location of the upcoming target is known even though its features are not (Awh et al., 2003). In contrast, the effects of feature-based attention can be observed even when an irrelevant feature is superimposed on the target feature so that spatial attention is of no use at all (Saenz et al., 2002; Scolari et al., 2014).
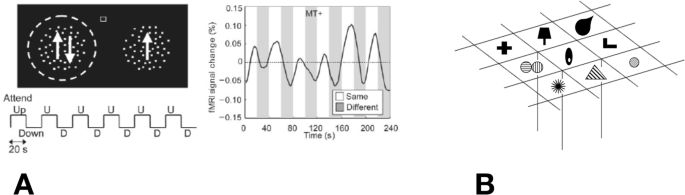
Interestingly, the attentional benefit that is directed to one feature of an object appears to extend to other features of the object. O’Craven et al. (1999) superimposed a face and a house, with one moving whereas the other was stationary. When observers directed their attention to the motion, for example, there was an enhanced activation for the cortical representation of the other attributes of the moving object but not for the other attributes of the stationary object. This result suggested that the processing of all attributes (features) of an attended object will be enhanced whether or not they are relevant to the task. Similar results were reported in an EEG study by Adamian et al. (2020) and in an MEG study by Schoenfeld et al. (2014). These studies were testing top-down activation of feature-based attention—the feature to attend to was specified on each trial and the extension of attentional benefits to task irrelevant stimuli only occurred when they shared the attended feature. Feature-based attention can also be allocated without prior specification of the feature to be attended. For example, during saccades, the attention directed to the saccade target also extends to other stimuli that have the same direction of motion as the target (White et al., 2013).
Liu (2019), in a recent review, continued Müller’s (2014) earlier proposal that feature-based attention is controlled by the same network of frontoparietal regions responsible for space-based attention. There is surprisingly little physiological evidence for an area that controls the allocation of feature-based attention in the same way that saccade areas have been shown to control space-based attention (Awh et al., 2006; Moore & Zirnsak, 2017). We could imagine a feature gain map, equivalent to a spatial gain map but with dimensions of features rather than space. For example, the region of inferotemporal (IT) cortex (Fig. 2B) could act as such a feature map (Tanaka, 2003). Once a feature is activated here, downward projections to all locations with that feature would allocate attention to appropriate locations throughout the visual field. While this may be a plausible structure for the control of feature-based attention, this region of IT cortex in particular is not a likely candidate because the features here are more complex than the simple features that are the basis of pop-out visual search (Treisman & Gormican, 1988) and feature-based attention tasks (Saenz et al., 2002). However, the features used in feature-based attention tasks have not yet explored the full range of features that may be supported (see Box 1). Whatever the case, the anatomy underlying feature-based attention remains a missing piece of attentional control—a missing piece that we will uncover later in this review.
Duncan (1984) was the first to note that attention could select one of two items that were at the same location (Fig. 3, left). This extended the simple idea of space-based selection, by demonstrating that attention could selectively enhance the processing of a subset of features at the same location in the visual field. This initial evidence indicated that there was some object-specificity in selection. Blaser et al. (2000) extended this result by superimposing two Gabor patches that smoothly and independently changed their orientations, colors, and bar widths over time. Participants were able to keep track of the features of one of the two objects, accurately reporting the direction of any abrupt changes in two properties, say, the target’s orientation and color. However, they could not track one property of each object at the same location even though they still had to report only the changes in two features, say, the orientation of one and the color of the other.
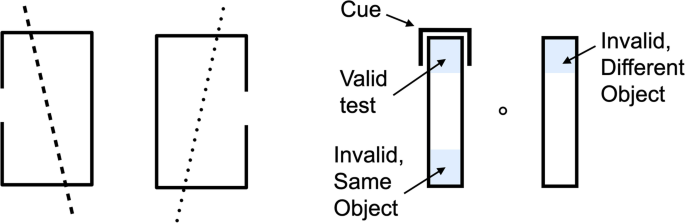
Egly et al. (1994) further confirmed and extended this object-specificity by showing that attention, once directed to part of an object, can be allocated to locations within the object faster than to locations outside the object (Fig. 3, right). A large literature now documents numerous ways in which the spatially cueing of one part of an object can lead to attentional facilitation at uncued locations of the same object (Chen, 2012; Müller, 2014).
Many of the studies of object-based attention have used the two-rectangle style of Egly et al. (1994). Effects of object-based attention have also been found using paradigms that show observers two overlapping surfaces (Mitchell et al., 2004; Valdes-Sosa et al., 2000), or superimposed objects (houses vs. faces: O’Craven et al., 1999; Tong et al., 1998) or adjacent, real objects (Malcolm & Shomstein, 2015). Across this wide range of paradigms, outcomes have been quite consistent: when response time is the measurement, a response advantage of about 15 ms is found for tests at uncued locations within the object versus uncued location in an adjacent object.
Francis and Thunell (2022) recently reported that this modest 15 ms effect size has led to an “excess success” in reporting object-based experiments based on the original Egly et al. (1994) paradigm. Nevertheless, they did show that with the appropriate number of participants, 264 in their case, the two-rectangle measure of object attention holds up (at 14 ms). Possibly the objects typically used in the experiments are not very salient.
Malcolm and Shomstein (2015) did find stronger effects using real world objects (around 50 ms for the same object, invalid cue advantage). Future, behavioral, EEG and fMRI experiments could give a better picture of the effect size and spatial extent of object-based attention (see Box 1).

In many of these studies the target is presented in advance allowing its shape to reach a high level of shape representation where it may guide the allocation of attention in a top-down manner. In the two-rectangle experiments Egly et al. (1994), the rectangles are irrelevant to the task. Nevertheless, the presence of the rectangles before the flashed cue gives the rectangles the chance to exert top-down influences. This lead time does not appear to be necessary—the same-object advantage has been found with invisible rectangles (Lin & Yeh, 2015; Zhang & Fang, 2012) suggesting that the object’s involvement does not require awareness. Attentional capture by threat stimuli (Tamietto & de Gelder, 2010) is another example of object-based attention without object preview. No particular low-level feature is salient in these stimuli, instead, processing must reach the level of objects preattentively for the threat value to attract attention.
One study of multiple object tracking (Scholl et al., 2001) suggests that object processing is obligatory—paying attention to one part of an object automatically brings attention onto the whole object. This study took a standard tracking display but joined each target with a distractors linking them together with a bar. The end points of the bars moved on exactly the same trajectories as in the standard display and if an end point could be considered an object, tracking should not have been affected. However, performance plummeted, suggesting that the object is the minimum unit on which attention can operate.
Cohen and Tong (2015) and others (Al-Aidroos et al., 2012) suggest that feedback from object areas to early visual areas underlies the processing advantages seen for the attended object. This requires that the feedback to early visual areas targets the low-level features corresponding to the attended object at their actual locations. Cohen and Tong (2015) found evidence for this object-specific enhancement even when two targets (a house and a face) overlapped. They proposed that the feedback from object-specific areas (face and scene areas in particular) projects to the complex cells at the object’s location. This involvement of object-selective areas is consistent with tests on patient DF who has bilateral damage to the lateral occipital area that mediates object processing (de-Wit et al., 2009). DF showed no evidence of object-based enhancement in two standard paradigms. Although DF had normal spatial orienting in Posner cueing tasks (Downing & Pinker, 1985), the cueing effects were completely uninfluenced by object structure.
While the source of the direct projections to early visual areas may arise from object-specific cortex, frontal and parietal areas may control which object representations are activated (Serences, 2004). This top-down activation would be based on task relevance or expectation.
These three systems have very different modes of operation (Kravitz & Behrmann, 2011; Müller, 2014), two being spatially constrained and one nonspatial. In the discussion, we consider a variety of proposals for how the three systems may overlap (Liang & Scolari, 2020; Shomstein & Behrmann, 2006; Vecera, 1994). For example, in his 2014 review, Müller (2014) suggested that feature-based and space-based attention are guided by the same cortical networks with the difference that feature-based attention acts globally, while spatial attention is more local. However, according to Müller (2014), “very little is known concerning the direct comparison between feature- and object-based attention” (p. 133). Our next section digs deeper into the functioning of object-based attention and does uncover a strong link to feature-based attention.
Here we do not review the evidence for object-based attention (Chen, 2012; Francis & Thunell, 2022; Reppa et al., 2012), instead we cover the prerequisites to object-based attention. First, concerning the targets of object-based attention, we see that visual input may reach, preattentively, the level of complete object representations. Second, we examine several possibilities for the allocation of attention to objects and find that the most likely process involves projections from object areas to the locations and features of the object. This recovery of location from high-level areas has become more plausible with the recent work on autoencoders (Hinton, 2007; Hinton & Salakhutdinov, 2006; see Recovering Features and Locations section). We also find that attention can be rapidly allocated not just within an object defined by bounded contours, but also to the disconnected members of a perceptual group, matching the defining property of feature-based attention.
The definition of an object has been debated for a long time (Feldman, 2003; Palmeri & Gauthier, 2004; Scholl et al., 2001; Spelke, 1990). We need only think of the wide range of things that we can consider as an object (a pencil, a swimming pool, an entryway, the moon, a chair, a flame) to see the challenge. Although it is clear that no single definition will hold, we can agree that connectivity is a general property of objects: They are connected, bounded volumes with an inside and an outside. They have a shape and a three-dimensional configuration of features. These are the properties—features and their locations—that object-based attention uses to boost relevant target activity at earlier levels. Separate entities that are connected can form the parts of a larger object, like the wheels and frame of a bicycle. But disconnected entities like an orchestra, a flower arrangement or a flock of birds are groups, not objects. The connectivity that glues together the parts of an object may be mechanical, like that for sweaters or a tractor, or simply adjacency like that for a pudding or a tornado, a flame or a cloud. While connectivity is fine as a defining property for objects in the world, objects in our perception, whether real or depicted, raise further issues because occlusions can break the object into separate parts, destroying visual connectivity. We could appeal to the connections that would have been there if the occluder were absent but to do that we need to make the best grouping of the visible parts using Gestalt principles of Good Form (known object shapes) and connectivity. But these processes just tell us that we know what objects are because we already know what objects look like. In the end, it is object knowledge that determines what is an object and this object knowledge resides in the object areas of the cortex. Interestingly, this leads us to propose a brain-based definition—objects are what object-areas learn to represent. For now, this is completely circular. Further study of responses in object-based areas may reveal actual, general properties true of all objects or may show instead that, like the categories of, say music and art, objects are a consequence of learning and the elements in the set may differ between individuals and cultures.
Whatever objects are, some neural representation of objects must exist preattentively for attention to be directed to them. According to Wolfe and Bennett (1997), preattentive processes can segment visual input into candidate objects that they called preattentive object files. Rensink (2000) proposed calling these preattentive objects, “proto-objects” and described them as “volatile units of visual information that can be bound into a coherent and stable object once accessed by focused attention” (Walther & Koch, 2006, p. 1395). Von der Heydt (2015) reported that grouping cells in area V4 are the first to represent an object. He proposed this to account for border ownership units in V2 that responded to contours based on their location relative to the object they belonged to. Franken and Reynolds (2021) recently reported columns of border ownership cells in V4 that may correspond to this object-specific representation. These early representations of grouped contours might serve as proto-objects but if so, they lack the identity and semantic information necessary for the results seen across the extensive literature of high-level unconscious processing (reviewed below). We will later propose that these early V4 units participate in the object’s representation but cannot be, on their own, the preattentive representations that are required for object-based attention. Based on the unconscious processing literature we will take a very different stance and claim that the preattentive object representations can reach the level of identity and semantic connectivity and this does not necessarily change qualitatively once accessed by attention. We will then address and explain the apparently contradictory findings, consistent with Rensink’s (2000) proposal, that attention is necessary to bind features together and that without attention, there are no objects.
Research into the neural responses to unattended visual stimuli and their behavioral consequences challenge the view that attention is necessary to form object representations. Several studies have reported high-level processing in animals under anesthesia, for example, with object-specific responses of neurons in the inferotempral cortex (Gross et al., 1972; Tanaka et al., 1991). Deeprose and Andrade (2006) reviewed studies on priming in humans during anesthesia and concluded that perceptual priming takes place in the absence of conscious awareness. There is also a broad literature in human behavior showing that preconscious and preattentive representations can reach the level of objects and words (Ansorge et al., 2014; Elgendi et al., 2018; Van den Bussche et al., 2009). Semantic priming has been demonstrated even when participants are unable to identify the prime (Yeh et al., 2012) or unaware that there has been a prime (Mack & Rock, 1998). Another piece of evidence for preattentive objects is the capture of attention by threat stimuli (Tamietto & de Gelder, 2010). For example, West et al. (2009), using temporal order judgements, found that when two faces were presented side by side, angry faces appeared first (prior entry). Low-level features cannot explain the difference in appearance order—there was no angry face advantage when the faces were inverted. The objects must reach a level of identification preattentively for the threat value to draw attention and speed its processing. Several authors also claim that the gist of a scene can be categorized rapidly without consciously identifying the objects in the scene (Greene & Oliva, 2009; Potter, 1976; review, Wolfe et al., 2011). Finally, a number of studies (Bahrami et al., 2008; Shin et al., 2009) have reported that unconscious processing can be boosted if a spatial cue directs attention to the region of the unseen stimulus. These results suggest that the downward projections of spatial attention have a generalized faciliatory effect on processing even on stimuli that never reach awareness. Although these studies, and others to be discussed below, do support extensive processing of unconscious targets, others suggest that this remains controversial as there may be contamination by weak conscious perception (Zerweck et al., 2021).
If there are preattentive objects, it is reasonable to ask whether these can support classic object-based attention effects. First, a number of studies have shown that salient objects attract attention even if they are not seen (Huang et al., 2015; Jiang et al., 2006; Lin & Murray, 2013; Lu et al., 2012). Of course, if attention is required for a stimulus to enter awareness (Cohen et al., 2012), then salient stimuli must be able to attract attention to themselves. If attention could only operate on stimuli that were already in consciousness, there would be no way for new stimuli to enter awareness. Second, there is clear evidence that object-based attention operates on cued objects even if they never reach awareness. Four studies have reported object-constrained spread of attention for objects that remained invisible. Chou and Yeh (2012) used Egly et al.’s (1994) two-rectangle method but suppressed the visibility of the rectangles with continuous flash suppression (Koch & Tsuchiya, 2007). They reported that the same-object advantage was found whether or not the participants were aware of the rectangles. Using masked two-rectangle stimuli, Norman et al. (2013) reported a significant object-based attention effect under conditions where the selected object indeed remains undetectable. Zhang and Fang (2012) also used the double-rectangle paradigm but presented them briefly at low contrast. In a control experiment, participants were at chance in reporting the orientation of the rectangles, yet the low contrast rectangles produced the classic object-specific cueing advantage that was not statistically different from that found when the rectangles were visible.
Taken together, these results provide strong evidence that the preattentive entities targeted by object-based attention can be fully developed representations of objects. They act as meaningful words or salient human figures, and their parts are unified. There is no evidence that they are processed less fully than attended objects for the purposes of establishing their spatial extent and identity. Of particular interest, the object-based advantage was found even if the object representations that guided attention never reached awareness. Clearly, if they do reach awareness, objects can be more fully processed for the requirements of more complicated tasks, especially those requiring the scrutiny of the constituent parts of the object. For example, reporting whether the word “administer“ contains an even number of vowels, or whether a book is for children or adults would only be possible once the word or the book reached awareness. For the simple purposes of object-based attention though, the evidence is compelling that the representations of preattentive objects may reach that of fully developed objects.
Many have argued that objects only exist once they are attended, because attention is required to put all their pieces together (Rosenholtz et al., 2012; Treisman & Gormican, 1988). According to this view, “objects” are just co-localized collections of features prior to the arrival of attention. Illusory conjunctions (Treisman & Schmidt, 1982) are evidence for this unbound state as features of one object may migrate to another under conditions of high attentional load, a case that is seen in the extreme with Balint’s patients (Friedman-Hill et al., 1995). In a series of experiments, Wolfe and Bennett (1997), also reported evidence that preattentive objects are only loose collections of features. They failed to find any preattentive representation of overall shape and concluded that the representation of a visual stimulus’s shape required attention to bind the features together. For example, they found that it was very hard to distinguish plus-shaped crosses made of red and green rectangles (Fig. 4, left) that differ in which color is vertical and which horizontal. Their argument is that these shapes are seen just as plus signs with some red and some green without specifying which is where, and this makes it hard to pick out the odd one unless we attend to each in turn to put the features in their correct locations. They also showed it was hard to find a non-chicken among chickens (Fig. 4, right) again indicating that putting the parts together required attention.
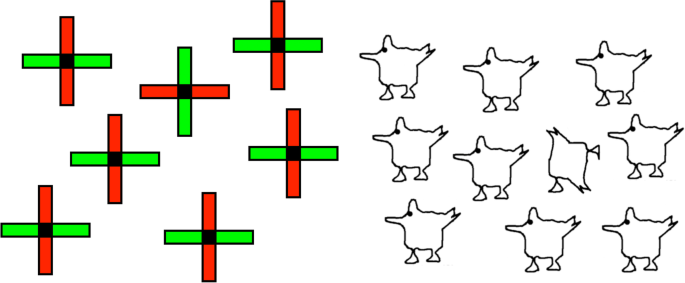
How can the visual search literature show that objects are just bundles of features before attention arrives, whereas the review of unconscious processing in the previous two sections suggests that objects can be fully defined preattentively? There are a number of factors that may explain this discrepancy. The first is that the search task requires the participant to report a difference between stimuli (e.g., different color assignments, or chicken vs. nonchicken; Fig. 4). Detecting the difference may be hard whether or not the representation is one of objects or bundles of features. If all the chickens are represented preattentively as chicken objects, detecting the one non-object (the jumbled chicken) is unlikely to be an easy search any more than detecting the absent diagonal feature of the O among Qs (Treisman & Gormican, 1988). Difficult discrimination is not proof that an object-level description has not yet been formed.
A second possibility is that object representations are not actually all that specific. Certainly, they cannot be a complete representation of the object’s features in photorealistic detail. Perhaps some features are part of the object description without including their spatial relations to the others. So, the items in Fig. 4 on the left might represented as objects that have a plus sign shape with some red and green arms. If you want more detail, attention needs to scrutinize the object (Hochstein & Ahissar, 2002). Evidence that descriptions are only approximate is not evidence that an object-level descriptions have not been formed. An object whose shape is poorly defined (e.g., blurry, through a mud splattered windscreen) may nevertheless be similar enough too, say, a car, to be seen as a car. It is the low-level features that are poorly registered but the configuration is sufficiently characteristic to trigger its identity as a car, a labelling with semantic properties that go far beyond those of a feature bundle.
Egly et al. (1994) showed that when part of an object was cued, attentional benefits were found at other locations within the object even though they had not been cued (Fig. 3). The question here is how attention was allocated to the rest of the object out to its borders. Where and how does that happen? Some authors have proposed explanations for the performance advantage within an object that invoke a spread of attention (LaBerge & Brown, 1989; Roelfsema et al., 1998). Others have mounted evidence against spreading as a mechanism. For example, attentional shifts to uncued locations may be faster within the same object, as compared with shifts to different objects (Brown & Denney, 2007; Lamy & Egeth, 2002; Luzardo et al., 2022). Alternatively, the effect of the object may be to prioritize the allocation of attention to locations within its shape (Shomstein & Yantis, 2002). In all these cases, the object’s form mediates the allocation of attention. We first consider three different ways to limit the spread or shift or prioritization of attention: low-level spread; object shapes on salience maps; and control from object areas. We then examine the evidence from overlapping, moving, and imagined targets to see how these results constrain the mechanisms of allocation.
LaBerge and Brown (1989) among others (Roelfsema et al., 1998) proposed that when spatial attention is allocated to a part of an object, it spreads from its original focus to all parts of the object (Fig. 5, left). One explanation would be that the extra gain provided by attention can propagate over horizontal connections and that these connections are blocked once the activity, whatever it may be, reaches the object border. This is like the brush-fire or region-filling processes proposed for discovering the object’s shape developed in computer and computational vision (Grossberg & Mingolla, 1985; Hojjatoleslami & Kittler, 1998; Pavlidis & Liow, 1990). This process keeps expanding the attended area across connected regions as long as the properties remain reasonably constant. Once a discontinuity is reached, say, a change in brightness, depth, or color, the process stops. As an example, Ekman et al. (2020) show how activation in V1 extends from the cued end of an arc to the opposite end, avoiding the superimposed but uncued arc (Fig. 5, right). L. Huang et al. (2022) reported a related spread of attentional benefit along a U-shaped target cued at one end. Performance improved in the uncued middle of the target before it did so at the uncued end. However, this low-level spreading proposal does not hold up as the sole mechanism for the allocation of object-based attention. For example, when one face of a cube is cued, the benefits are also found on other faces even though there is a clear edge between the two surfaces (Erlikhman et al., 2020). Moreover, attention can be allocated to one of two objects at the same location (Overlapping Targets section) and can extend across disconnected regions (Grouping and a Bridge to Feature-Based Attention section). None of these properties is possible for a region-growing process.
Indeed, several articles have presented evidence against the hypothesis that attention spreads automatically throughout the object’s extent when part of the object is cued (review, Shomstein, 2012). One alternative proposed for the (Egly et al., 1994) two-rectangle task is that the object speeds the shifting of attention to another location within an object compared with a location on another object (Brown & Denney, 2007; Lamy & Tsal, 2000; Luzardo et al., 2022). A second alternative is that a higher priority is assigned to locations within the object (Lee & Shomstein, 2013; Shomstein & Johnson, 2013; Shomstein & Yantis, 2002) so that they are analyzed first. For example, once the object is cued, any search for a probe element would prioritize locations within the object rather than elsewhere. Both of these alternatives focus more on the mechanism by which attention accesses locations rather than assuming some uniform, automatic distribution of benefits throughout the object. Importantly, rather than discovering its shape by spreading activation out to the object’s borders (LaBerge & Brown, 1989), these alternatives both depend on an existing representation of the object’s shape to prioritize access to locations within the object.
The proposal of prioritization is an alternative to gain as a mechanism for attentional benefits—rather than boosting gain, attention would boost priority. In this case, an object’s features at the early levels of visual cortex would be selected first for further processing. This is equivalent to V1 acting as a salience map where the salience was not computed locally but allocated to the object’s locations by downward projections from object areas. When we say that attention boosts activity, it can be taken either as classic gain—boosting actual neural activity—or boosting priority. However, priority may be realized by increasing neural activity so the two proposals may be the same thing. Whatever the case, these alternatives depend on downward projections from object-specific areas to facilitate access to locations within the object. The following sections examine where the object’s shape is represented and how it mediates the projection of attentional benefits to early visual areas.
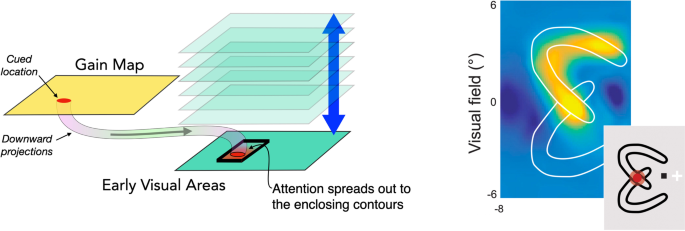
Is the allocation of attention guided by object-shaped activations on gain maps (Fig. 6)? If this were the case, then the downward projections that carry the attentional boost to low-level areas would fill the whole region of the object shape and directly mediate object-based attention—as suggested by Knapen et al. (2016). If this were the case, there would be a few issues to consider. First, gain maps like those in posterior parietal cortex (PPC), frontal eye fields (FEF) or subcortical areas (superior colliculus [SC]) have large receptive field sizes and so lower spatial resolution than early visual cortex. As a result, the projections from these areas to early visual cortex would cover a blurry version of the object. Attention does have low resolution (He et al., 1996; Intriligator & Cavanagh, 2001) but there have been no studies yet that explicitly look at the resolution of object-based attention measuring, for example, the profile of attentional benefits as the probe location moves from inside to outside the cued object. Second, the selection of an object not only requires enhancement of the appropriate region of space but also enhancement of the subset of features that define the object. This is critical when selecting one of potentially several overlapping (e.g., partially occluded or transparent) objects. Since the gain maps in PPC, FEF and SC are two-dimensional, retinotopic representations, they have no way to deal with overlapping objects on a purely spatial basis, an issue we address in Overlapping Targets section, below. Lastly, there would need to be some way to get the object shapes from object areas onto the salience or gain map at the right location. This is a nontrivial requirement which we will consider in the next section and in the Anatomical Basis section.
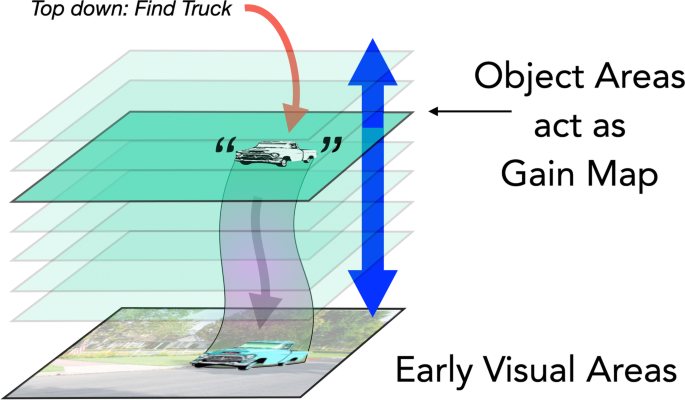
The next sections deal with findings in object-based attention that allow us to evaluate these three allocation mechanisms.
Here, we present evidence from overlapping, moving, imagined, and grouped targets that suggests that attentional allocation originates in the object areas of ventral visual cortex. Moreover, the results from attention allocated to groups, in the Grouping and a Bridge to Feature-Based Attention section, below, will suggest that feature-based attention and object-based attention may depend on the same mechanisms.
The findings that attention can target one of two overlapping objects (Duncan, 1984) is critical in understanding the process of selection. Even if location information could be recovered from activity at higher levels, location alone would not be sufficient to guide attention in this case. To do so, the selection process must be able to localize the object’s features. In Duncan’s original study on object-based attention, the two objects were only partially overlapping (Fig. 2).
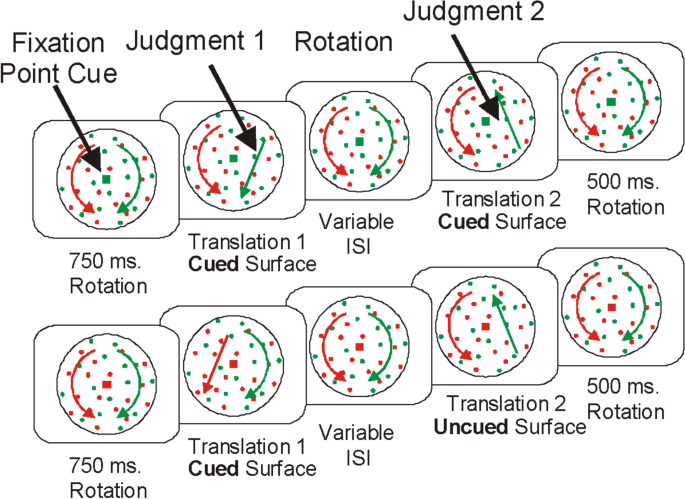
To address this, Valdes-Sosa et al. (2000) and Mitchell et al. (2004) used fully overlapped motion fields (Fig. 8). They again found an object-based benefit: Selection of one plane improved the detection of a second event on the same plane, but not on the other, even though both planes were completely overlapped. These experiments might be seen as tests of feature-based attention rather than object-based attention, but even so, equivalent findings have come from fMRI studies of attention to overlapping objects, most frequently faces and houses (Cohen & Tong, 2015; O’Craven et al., 1999). So, the ability to select one of two overlapping objects is robust. How can attention be allocated to only one of two overlapping objects if the controlling map (Itti & Koch, 2001) and the receiving area were both 2D retinotopic representations? Certainly not by lateral spread on the gain map, or at the level of the activation in early visual cortex where the representations of the two objects are intermingled. One possibility is that depth or object-defining features could disambiguate the two targets. This would require that the gain map, say the superior colliculus or LIP, differentiates depth planes and/or features. There is only meagre evidence of feature specificity in areas that might be controlling attention (e.g., some preferred motion cells in LIP; Fanini & Assad, 2009) and little or none of depth specificity (Sparks, 1999). The one remaining possibility is that the downward projections to early cortex are from object areas (Cohen & Tong, 2015)—these projections can represent object features including depth. In the Cohen and Tong (2015) study, for example, the projections could be to units that code facial features versus house features. The findings with overlapping stimuli require that downward projections from object areas can target not only the object’s location but also its features, a substantial challenge. This ability to project to the locations and properties of a target object is one of the key properties of autoencoders that make control from object areas a viable proposal (see Recovering Features and Locations section).
If an object is cued, the attentional benefits are available throughout the object (Egly et al., 1994) and its features (O’Craven et al., 1999). But what happens if the object moves before the probe is presented. Would the attentional enhancement remain at the original location of the object or follow the object to its new location? Several studies show that the benefits do move with the cued object and do not remain at the actual location of the cue. For example, Lamy and Tsal (2000) and Gonen et al. (2014) presented a pair of rectangles and cued the end of one of the rectangles. The rectangles then moved to new locations and the benefit for the uncued, within-object location moved with the cued rectangle to its new location. These results are in many ways equivalent to those of the multiple object tracking task (Cavanagh & Alvarez, 2005; Drew et al., 2009; Pylyshyn & Storm, 1988) where attention directed to an initial set of targets follows these targets around until the end of each trial. The visual system deploys attention to where the cued target is now, not to where it was, so that attention, once directed to an object, remains with the object. fMRI studies have shown that frontal and parietal areas are involved in keeping track of the attended targets in the multiple objects tracking task (Culham et al., 1998, 2001; Howe et al., 2009). This supports the claim that object selection is guided by frontal and parietal areas which then must engage the representations of the selected targets in object areas. As indicated by the overlapping target findings above, only object areas have both the location and feature information required to accurately direct attention when objects are superimposed.
If attention is directed from representations in object areas, then we might expect that object-based attention effects would follow any activation in these areas, even in the absence of sensory input. This appears to be the case. First, we can organize ambiguous patterns into specific shapes by attending to elements in the structure that conform to the shape, which can be suggested verbally (Attneave, 1971; Huang et al., 2007). We can also impose a mental image of a shape or letter on a 3 × 3 or 4 × 4 grid and find attentional benefits for probes that fall on squares that are part of the imagined shape, as opposed to squares that are not part of the shape (Farah, 1989; Ongchoco & Scholl, 2019). Finally, results from fMRI studies show that attention to a target’s location activates early cortex at the expected location even before the stimulus is present (Kastner et al., 1999) and, critically, the activation has the shape of the expected object (Silver et al., 2007). Because object-shaped effects are observed when no object is present in the image, the shape of the attentional enhancement must be driven by the downward projections themselves as opposed to an allocation out to object boundaries in early cortex (Ekman et al., 2020).
Does object-based attention operate on groups—if attention is cued to one element in a group, is it also allocated the remaining elements? Grouping may be an initial stage in putting together an object’s many adjacent bits and pieces but sometimes the pieces are not connected even though they are strongly grouped. Although connectedness is a basic property of most objects, it is not a property of groups, like a flock of birds, or a line of chorus dancers. Matsukura and Vecera (2006) suggested that object-based attention can select multiple-region objects, provided that the regions follow perceptual grouping cues. Driver and Baylis (1998) also proposed that selective attention acts similarly on objects and on unconnected elements grouped through adjacency or feature similarity. If we accept that groups can be the targets of object-based attention, then groups, like objects, must also exist preattentively. Indeed, there is strong evidence that grouping occurs in the absence of attention (Lamy et al., 2006; Moore & Egeth, 1997).
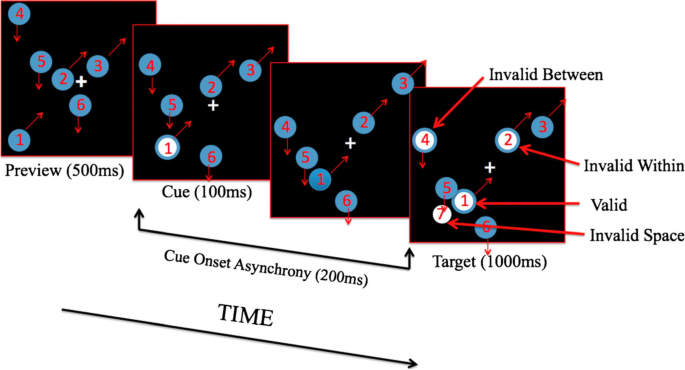
Does attention extend across the members of a group? The first evidence comes from studies where the standard adjacent rectangles were divided in two by an occluding bar (Haimson & Behrmann, 2001; Moore et al., 1998). There was no continuous, within-object space over which attention could be allocated at early levels as in Fig. 7. Nevertheless, the object advantage was still significant. Additional evidence comes from grouped items that have no connections at all. Rafal (1994) replicated the object advantage reported by Egly et al. (1994) using two groups of circles arranged into parallel rows or columns instead of using two rectangles. However, they did not test whether the attentional advantage was confined to the discs or filled the spaces between them. To answer this question, Gonen et al. (2014) created two groups of three discs where each group had a common motion direction (Fig. 9). One group was cued by briefly flashing one of its discs (second panel, Fig. 9) then 200 ms later a test was flashed and participants had to respond as quickly as possible. The cued disc (white Disc 1 in last panel of Fig. 9) had moved on but the largest benefit was seen when the test flash was at this new location. Importantly, a probe on a second disc within the cued group also showed an advantage (Disc 2, Invalid Within, in last panel, Fig. 9). The response time for probes on discs in the other group (Disc 4, Invalid Between) or on empty space (Location 7) were at baseline. These results show that an attention benefit can cross empty space to enhance processing of other group members without enhancing the processing of all locations falling within the bounds of the cued group.
Other studies have looked at the allocation of attention across the characters within a word and found a similar within-object advantage, where the word is now the object (Li & Logan, 2008; Yuan & Fu, 2014). The two characters on top in Fig. 10 make the word although, the bottom word is situation. This has been called lexical object-based attention. Zhao et al. (2014) reported attention benefits also extend to learned pairs of patterns. Unlike Gonen et al. (2014) none of these studies tested whether the attentional advantage existed between the elements of the group.
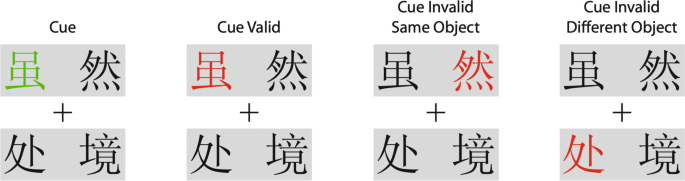
These results showing that object-based attention is allocated to the members of groups suggest that object-based attention may account for the properties of feature-based attention: the allocation of attention to disconnected elements that share the same features or part of the same word independently of their locations. Indeed, some authors propose that all objects are just local spatial groups (Vecera, 1994) and others have already noted that groups and objects can have the same status for selective attention (Baylis & Driver, 1992; Driver & Baylis, 1989; Kasai et al., 2011).
If feature- and object-based attention arise from the same system, what is the underlying mechanism? Feature-based attention appears to depend on global, feature-specific activation (Boynton et al., 2006; Liu & Mance, 2011; Serences & Boynton, 2007). If the mechanism underlying feature-based attention is global, feature-specific activation (Serences & Boynton, 2007), one consequence of feature-based attention will be seen when there are several items that share a feature—a group. But the grouping is not the mechanism mediating feature-based attention, it is a byproduct. In the case of object-based attention we suggest a similar global, object-specific activation that boosts the input signals of any matching object at any location in the visual field (see Box 2). When the to-be-attended target is a single feature, this mechanism reduces to the properties of feature-based attention.

The claim that feature-based attention is just object-based attention applied to groups is plausible, but there are two factors to consider. First, the experiments we covered in this section could easily be regarded as experiments on feature-based attention, rather than object-based attention. This is more of a question about semantics because the experiments could be framed in either category without much difficulty and, to an important extent, this emphasizes the overlap between the two systems when dealing with groups as objects. The second factor is more of a practical point. If the allocation of attention over an object and the allocation of attention across disconnected group members both rely on common mechanisms, do they also originate from a common cortical area? Are groups represented at the same level as objects? Groups and objects differ in that a group is defined by its common element not by its overall shape. In contrast, shape is one of the key features defining an object. The point of the group is to reveal the spatial extent filled by the grouped elements as input to further scene segmentation. It is not yet known if different areas represent groups and objects, but it would not be surprising. Even if they are at different levels in the cortex, we may assume that similar processes generate the downward projections from both areas to early cortex that confer attentional advantages.
The big challenge for object-based attention lies in directing the downward projections to the target objects and their features. How can the higher level representation of the object or group feed back to the locations and features that define the object in early visual areas? After all, the goal of higher level representations in object areas is to code for abstract properties and identity independently of size, orientation, pose or location (Logothetis & Sheinberg, 1996; Tanaka, 1996). However, more recent single cell studies have shown more sensitivity to position than was once thought (DiCarlo & Maunsell, 2003). Human functional magnetic resonance imaging (fMRI) studies also show that object selective areas are sensitive to position (Carlson et al., 2011; MacEvoy & Yang, 2012; Majima et al., 2017). These studies suggest that although position information is reduced for single neurons with large receptive fields in ventral areas of the visual cortex, it is retained at the population level. This is promising, but retaining some position information across the neural population in object coding areas does not reveal how this is used to target the source object in early cortex.
The development of autoencoder networks (Hinton, 2007; Hinton & Salakhutdinov, 2006) provides some insight into how a recovery of specific location and feature information might happen. Recent work in the perception of object properties, such as gloss, demonstrates the power of this unsupervised learning process in deep neural network autoencoders architectures (Fleming & Storrs, 2019; Storrs et al., 2021). The key to this architecture is the goal of matching the input and output states. The autoencoder first takes the high-dimensional input and compresses it through a series of layers into a low dimensional, coding level or latent value level (on the right in Fig. 11). This is then re-expanded through several decoding layers to reconstruct the original in a high-dimensional output layer. The network connections are adjusted until the output activity matches the input, a form of unsupervised learning. In a neural implementation, we assume that the low-dimensional, latent values are the high-level, object representations. Furthermore, the only way to have comparable, high-dimensional, input and output layers is for them both to be in the same areas of cortex. This generates a closed loop from early retinotopic areas up to object areas, and then back to early retinotopic areas. As a very useful bonus, when a particular object’s representation is active on the latent value level, projections from that level will target the locations and features that belong to the object, despite the impoverished representation of location at the object level. Seen in this way, the ability to modulate input activity either by a complete encoding to decoding sweep through the system, or through top-down activation of the learned latent space (object) nodes even in the absence of sensory input, can serve a second purpose: object-based attention. It is noteworthy that this property emerges not specifically to support object-based attention, but rather as a byproduct of learning to efficiently internalize representations of the external world.
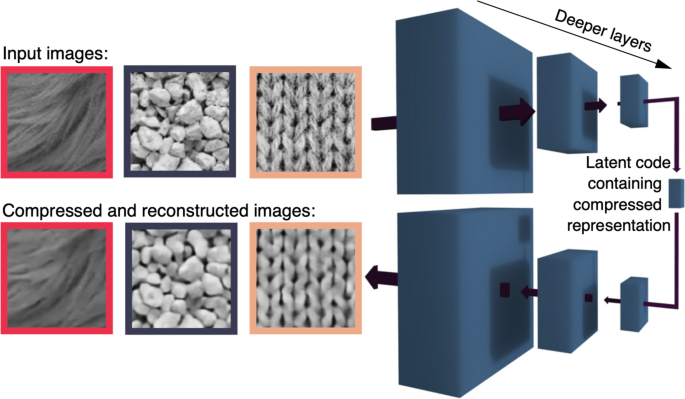
Autoencoders have been used to model the processing of visual information in humans for the perception of material properties (Fleming & Storrs, 2019; Storrs et al., 2021) and for spatio-temporal and chromatic contrast sensitivity (Li et al., 2022). The results of these modeling efforts are descriptive—they can show high-level representation of image and scene properties. In a more general application to the visual system for object recognition (Han et al., 2019; Le, 2013), the higher-order, low-dimensional representation is specifically intended to be the set of familiar objects that the object area can recognize. Convolutional autoencoders have also been developed to deal with issues of encoding targets across variations of location, size, and orientation (Hinton et al., 2011; Le, 2013; Oyedotun & Dimililer, 2016).
We use autoencoders here as a placeholder or proof of existence of some network configuration that can recover the location and feature information from population level activity, filling the missing link for the operation of object-based attention. Proposing that autoencoders fill this role does not yet provide us with any novel predictions for behavior or physiology that are specific to autoencoders. They require projections from early visual areas to object-specific areas and then projections back to the early areas to target object features, as would any architecture for visual processing and object-based attentional control. There are two main differences between autoencoders and other hierarchical neural architectures. First, the autoencoder has its most compact representation (fewest units) in the middle followed by decoding to a high-dimensional representation. In typical neural nets, like those focused on recognition (e.g., AlexNet, GoogleNet), it is the final level that has the fewest units. And second, in typical neural nets, the final compact layer is where error signals are extracted between the actual output and the desired output. In contrast, autoencoders compare the high-dimensional input and output representations and any deviation between them is used to drive the evolution of the network. In the neural implementation, the input and output representations must both be in the same early visual areas in order to make this comparison—there are no other areas that are of sufficiently high dimensionality. This comparison operation relies on the projections, feedback, from the high order representations (object areas). Typical neural nets do not have this feedback from the highest level to the input layer for error extraction and so they do not provide the possibility of targeting object features and locations that an autoencoder architecture does.
Finally, this autoencoder approach has close links to the predictive coding approach (Friston, 2010; Marino, 2022) where the brain learns to predict early activity from higher level representations by reducing prediction error. In both cases, downward projections from higher level representations of objects can target the locations and features of the object. Despite this similarity, predictive coding acts to suppress information predicted by higher level areas—whereas attention’s goal is to facilitate its processing.
We have proposed that autoencoders fill the missing link between object areas and the target object’s low-level features and locations. What other advances have been made in computational modeling of attention and specifically, object-based attention? Tsotsos et al. (1995) modelled attention as a selective spatial filter that starts with the most salient upper-level unit and suppresses lower units that do not contribute to it. Later work extended the selection process to include features and objects (Tsotsos et al., 2016). Computational models generally take a biased competition approach, identifying high salience locations or objects of interest (Rao, 1997; Sun & Fisher, 2003; Wu et al., 2004; Yu et al., 2015) and then prioritizing their processing through a hierarchy of processing levels while suppressing activity that is not contributing to the salient location or object or feature. The emphasis on object-level representations matches our focus on object-specific areas as the source of object-based attention. There is a great deal of overlap between our proposal and computational modeling on the conceptual level—for the obvious reason that both approaches are attempting to explain the same performance properties. Although computational models have captured many of the properties of object-based attention, they have not yet revealed any properties that were not already known. In contrast, our architecture for object-based attention makes the following novel points: (1) the architecture unifies feature-based and object-based attention; (2) it identifies the anatomical sites for different components of object-based attention; (3) it reveals how autoencoder networks can solve the feedback specificity problem; (4) it allows for the global projection of object-based benefits; (5) it demonstrates the importance of preattentive, identity-level object representations; and (6) it predicts suppressive surrounds in object space. Nevertheless, there will clearly be important, further advances in computational modeling of attention, some of which may follow from our proposals here.
Our review has led to the following summary of likely properties for object-based attention.
What is new here? Based on the literature we reviewed, we first conclude object-based attention is controlled by activity in the object-selective areas of ventral visual cortex. This differs from some proposals of spread guided by object boundaries in early cortices (LaBerge & Brown, 1989; Roelfsema et al., 1998), but it is in line with the conclusions of fMRI studies (Cohen & Tong, 2015) where one of a pair of superimposed objects could be selected by attention. The critical point of these studies, as well as those testing superimposed moving surfaces (Mitchell et al., 2004; Valdes-Sosa et al., 2000), is that only object areas register the conjunctions of the features and their locations for a given object that would allow the targeting one of two superimposed objects. Neither the features alone nor locations alone would be enough to separate, for example, the superimposed houses and faces of Cohen and Tong (2015) study, and the other candidate areas in frontal, parietal or subcortical regions lack sufficient feature specificity to fill this role.
Second, we suggest that preattentive objects can be fully developed rather than unbound, feature-bundles. Since object-specific units in cortex have large receptive fields, it is possible that only relatively isolated target objects can preattentively activate the appropriate object-specific units.
Third, object areas have only crude retinotopy at best so that the required information of both location and features must be recovered from across units in the object area and elsewhere. We pointed to autoencoder-like, network learning (Hinton & Salakhutdinov, 2006) in the visual cortex to accomplish this recovery. Although plausible, the extent to which these autoencoder-like properties are realized in the brain remains to be demonstrated.
Finally, the finding that object-based attention can be directed to groups shows that object-based attention can be the source of feature-based attention. In 1989, Driver and Baylis noted that attention can be directed to perceptual groups whose elements are spatially separated. They used the flanker task (Eriksen & Eriksen, 1974) and found that distant flankers could influence performance more than nearby flankers if they grouped with the target (same motion, same color). Indeed, several articles suggest that groups have the same status as objects as targets of attention (Baylis & Driver, 1992; Driver & Baylis, 1998; Duncan & Humphreys, 1989). A consequence of this attention to groups that goes unmentioned in these articles is that it offers an explanation for feature-based attention. Specifically, since the group elements can be widely spaced and attention is directed only to the group members and not the space between them (Gonen et al., 2014), this creates the signature aspect of feature-based attention, a nonspatial, feature-specific allocation. We suggest a similar broadcasting of object-specific activation to all locations in the visual field. Störmer et al. (2019) have already demonstrated this property for faces. Specifically, when a face and a house were alternated at the same location and the participants attended to the face, face-specific evoked responses (N170) were found when task irrelevant faces were presented elsewhere in the visual field. It is not yet known whether this nonspatial allocation might be found for other stimuli nor whether it would generalize to other variants of the attended stimulus (Box 2). These downward projections from an active object representation may only be triggered by the presence of a matching object (anywhere in the visual field, as in Störmer et al., 2019)—its upward projections are received and generate downward reinforcement specifically to that object via the autoencoder network. This proposal does not include downward projections that are broadcast globally across the visual field, in effect searching for a match, as feature-based attention projections do. However, we cannot rule out that the downward projections are broadcast globally, despite how challenging the implementation would be. Indeed, such global, object-specific broadcasting would account for the reports of the decoding of a peripheral target identity from foveal ROIs when no stimulus is present there (Williams et al., 2008).
There have been many proposals to unite space-based and object-based attention. Vecera and colleagues (Mozer & Vecera, 2005; Vecera, 1994) and others (Logan, 1996; Shomstein & Behrmann, 2006) argued that objects were groups of locations so that space-based attention was simply object-based attention directed to a group that had only one element. However, these attempts to join space- and object-based do not avoid the necessity of object-level information. Scolari et al. (2014) have suggested that feature- and object-based attention are on the same continuum. Here, we extended their proposal based on the object-based attention effects seen for grouped elements (Gonen et al., 2014). Although the properties of all three systems can be seen in object-based attention, this does not mean that all attentional allocation is controlled by this one pathway. As mentioned earlier (Friedman-Hill et al., 1995), there are undoubtedly many “gain maps” that enhance performance throughout the visual system. We cannot say whether the object-based pathway dominates in the role of attention, in fact, the small effect size in the Egly et al. (1994) paradigm (Francis & Thunell, 2022) raises the question of whether it may play only a minor role.
This proposal for combined systems, while promising, runs into several strong counterarguments, especially from the patient literature. For example, patient DF has bilateral damage to the lateral occipital area that mediates object processing (de-Wit et al., 2009) and shows no evidence of object-based enhancement in two versions of the Egly et al. (1994) task. This is consistent with the control of object-based attention from object areas. DF nevertheless did show normal spatial orienting in a Posner (1980) cueing task. Finsterwalder et al. (2017) reported a patient with a thalamic lesion who was impaired in feature-based selection but not spatially based selection. Many behavioral studies also differentiate among the three systems. For example, Chou et al. (2014) used the external noise method to show that space-based attention operated through signal enhancement whereas object-based attention operated through noise exclusion. It appears that the allocation of attention through the object areas is not the only system available. As described in the beginning of this article, the evidence for the allocation of spatial attention through activation in the saccade system (areas FEF, PPC, SC) is quite compelling (Awh et al., 2006). Whatever the merits of mediating all three types of allocation through the object areas of cortex, this must be occurring in parallel with a purely space-based system that shares processing stages with saccade control.
Evidence for cooperation between separate attention systems comes from Donovan et al. (2017) who demonstrated that spatial attention was necessary to see object-based effects in temporal order judgments, implying an interaction between the two systems. The classic Egly et al. (1994) two-rectangle stimulus also shows evidence for the activation of multiple types of attention. Hollingworth et al. (2012) and (Müller & Kleinschmidt, 2003) reported gradients of performance benefits within the cued object. Although this could be due to incomplete allocation of attention throughout the object, it could also be the result of a focused space-based attention that drops off with distance from the cue, unaffected by the object’s shape, added to an object-based attentional benefit that has uniformly covered the full object shape. Kravitz and Behrmann (2011) also reported combined enhancement across all three allocation systems when the stimulus was appropriate for all three.
Throughout the review, the source of the object-specific feedback has been identified only as coming from object-specific areas of ventral visual cortex but several object-selective areas may be involved. For one, the representation of objects is associated with activity in the lateral occipital (LO) cortex (Kourtzi & Kanwisher, 2001; Malach et al., 1995). But Cohen and Tong’s (2015) results with overlapping faces and houses also show activity in face-specific areas (fusiform face area, FFA) and place areas (parahippocampal place areas [PPA]) among others as correlated with the attentional selection in early cortices (V1–V4). The visual word form area (Dehaene & Cohen, 2011) (VWFA) may serve this same function when words are the targets of attention (Li & Logan, 2008). One of the earliest areas that may have object-specific units is V4 (Franken & Reynolds, 2021; Von der Heydt, 2015). An object representation may therefore be a widespread activation across several of these areas.
There is substantial evidence from fMRI studies demonstrating the role of frontoparietal networks in specifying, top-down, which object representations are active. For example, Müller and Kleinschmidt (2003) used a whole-brain analysis of the BOLD response during a two rectangle cueing task and revealed strong activation in parietal and frontal regions as well as LO. Baldauf and Desimone (2014) reported that prefrontal cortex appeared to be a common source of top-down biasing signals for space-, object- and feature-based attention. FEF supplied signals for spatial attention while the inferior frontal junction (IFJ) supplied signals for object or feature attention. Serences et al. (2004) reported that posterior parietal and frontal regions were transiently active when attention shifted between spatially superimposed objects. Using event-related MRI in a two-rectangle cueing task, Shomstein and Behrmann (2006) showed that object-selective signals from the posterior parietal cortex control shifts of attention between object locations. Liu (2016) used the superimposed grating stimuli developed by Blaser et al. (2000) where participants are required to follow one of the two patterns with attention while both continuously changed color, orientation and spatial frequency. Liu (2016) was able to decode the attended pattern in several frontoparietal areas including the anterior intraparietal sulcus, frontal eye fields, and inferior frontal junction. Güldener et al. (2022) found that the right frontopolar cortex and other attention-related areas represented a novel stimulus prior to its arrival in awareness. These frontoparietal areas would project separately to the different object areas (e. g., LO, FFA, PPA). This hypothesis is further supported by recent findings of source-localized EEG data showing dynamic interactions between object-representations within the ventral-temporal and posterior-parietal cortex (Gurariy et al., 2022). One example of a potential projection pathway for these interactions comes from Takemura et al. (2016) who combined fMRI, diffusion MRI, and fiber tractography to show that the vertical occipital fasciculus (VOF) links dorsal and ventral visual cortex, connecting visual field maps between the two. These authors suggested that the VOF connects regions encoding object properties such form, identity, and color and to regions that register spatial information.
There is finally the aspect of surround suppression that may be common to all domains in which attention operates. In the spatial domain, attention to a target is accompanied by suppression of neighboring targets, shown behaviorally (Cutzu & Tsotsos, 2003; Mounts, 2000) and physiologically (Moran & Desimone, 1985; Schall et al., 1995). Similarly, surround suppression is seen in feature space where attention to one color, for example, will suppress responses to similar colors (Fang et al., 2019; Störmer & Alvarez, 2014; Yoo et al., 2018). Suppression of objects that are similar to an attended object may occur for object-based attention as well, although this has not yet been tested (Box 2).
Here we have focused on the processes underlying object-based attention: what are the targets of object-based attention; how is the selection controlled; and where does it happen? The literature in object-based attention is vast and we have undoubtedly missed articles, but the 200 papers we did survey made a compelling argument for three components. First, the targets of object-based attention are the features and locations in early visual cortices that receive downward projections from object representations in high level, object selective areas of cortex. Second, the object representations can be fully developed and activated either top-down from the frontoparietal attention network or bottom up from a salient cue located within the object’s boundaries. Finally, the downward projections from these non-retinotopic object areas can nevertheless target both locations and features due to autoencoder-like learning in the visual system (Hinton & Salakhutdinov, 2006). Interestingly, the object-based attention literature also included several examples of attention to groups with the conclusion that groups have the same status as objects as targets of attention (Driver & Baylis, 1998; Kasai et al., 2011). The evidence that attention can be allocated to the elements of a group (Gonen et al., 2014) led us to suggest that mechanisms of object-based attention and feature-based attention are closely linked, offering a unification of the two. Of course, a group that is a single element or location will allocate attention to a single location, matching the properties of space-based attention (Logan, 1996; Shomstein & Behrmann, 2006; Vecera, 1994). Despite the appealing possibility that object-based attention actually unifies all three modes of allocation, there is overwhelming evidence for the independent stream of spatial allocation controlled from saccade areas (Awh et al., 2006) suggesting that space-based attention may be controlled from both the object areas and the saccade areas. Finally, our exploration of object-based attention revealed several novel predictions: the link between feature-based and object-based attention; the anatomical sites for different components of object-based attention; the role of autoencoder networks; the global projection of object-based benefits; the preattentive, identity-level object representations; and the suppressive surrounds in object space. These new points should help guide further studies revealing in more detail how object-based attention works.
This review paper emerged from group discussions originally organized as part of the EPSCoR Attention Consortium starting in February 2021. The discussion group included David Sheinberg, Taissa Lytchenko, Aarit Ahuja, Gideon Caplovitz, Nadira Yusif Rodriguez, Patrick Cavanagh, and Peter Tse. Support came from NSF EPSCoR Award #1632738, from the Department of Psychological and Brain Sciences, Dartmouth College, from NSERC Canada RGPIN-2019-03938 (PC), from NIH R01EY014681 and R21EY032713 (DS), NSF EPSCoR Award #1632849 (G.C.).